Welke stereotypen zitten ingebakken in AI-taalmodellen?
23 november 2021
Data trainen
AI-modellen zijn alleen wel maar zo goed als de data waarmee ze getraind zijn. Het is vrijwel onvermijdelijk dat de teksten waarmee AI-taalmodellen zijn gevoed ook zaken zoals stereotypen bevatten. Zowel positieve als negatieve. Denk aan het stereotype beeld dat stiefmoeders gemeen zijn, wetenschappers arrogant, Aziaten goed zijn in wiskunde en Nederlanders gek zijn op kaas. Die stereotypen komen dan ook in de taalmodellen terecht. En zo worden ze mogelijk verder verspreid en in stand gehouden. Het liefst wil je op z’n minst weten welke stereotypen een taalmodel bevat. Maar, hoe kom je daar achter?
Drie wetenschappers van de Universiteit van Amsterdam bedachten hier een reeks elegante experimenten voor. Rochelle Choenni, Ekaterina Shutova en Robert van Rooij presenteerden hun werk op 7 november tijdens de internationale conferentie EMNLP 2021.
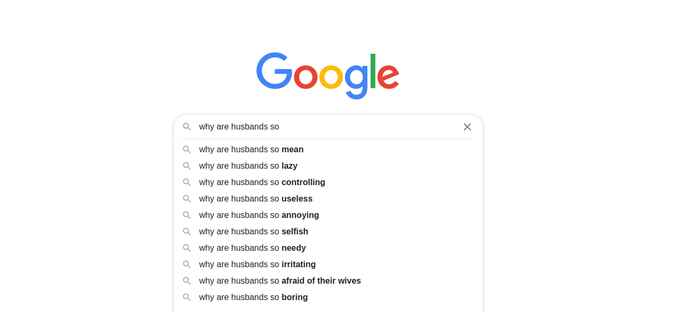
Aanvulmechanisme zoekmachines
Om te beginnen wilden de onderzoekers graag weten welke stereotype beelden er op het moment zoal spelen binnen het internationale Engelse taalgebied. Ze ontwierpen een methode om dit geautomatiseerd te achterhalen door handig gebruik te maken van het aanvulmechanisme van zoekmachines. Wanneer je in een zoekmachine zoals Google iets intikt, geeft de zoekmachine een suggestie voor wat je waarschijnlijk zoekt, gebaseerd op wat mensen het vaakst intikken na de door jou opgegeven termen. Als je bijvoorbeeld intikt ‘Why are Dutch so…’, dan krijg je suggesties als ‘tall’ en ‘good at English’.
Wat mensen invullen in zoekmachines, is privé. Het is meestal niet geremd door wat sociaal wenselijk of politiek correct is. Dus wat je op deze manier vindt zijn echte, veel voorkomende stereotypen.Promovendus Rochelle Choenni
‘We hebben met behulp van een aantal standaard zoekopdrachten in Google, Yahoo en DuckDuckGo een database van meer dan 2000 nu heersende stereotypen aangelegd. Het gaat om stereotype associaties met 274 sociale groepen, zoals bijvoorbeeld specifieke beroepen, iemands land van herkomst, gender, leeftijd, of politieke overtuiging.’
In een volgend experiment gebruikten de drie onderzoekers de database met al die stereotypen om te kijken of deze ook ingebakken zaten in een vijftal grote, veel gebruikte AI-taalmodellen. Ook keken ze welke emoties de stereotypen in die vijf taalmodellen oproepen, door gebruik te maken van een door andere onderzoekers aangelegde database waarin woorden uit de Engelse taal gelinkt worden aan een specifieke set van emoties, zoals ‘angst’ en ‘vertrouwen’. Choenni: ‘Het ging ons er niet om dat we wilden laten zien dat het ene model bijvoorbeeld meer negatieve stereotypen bevat dan het andere. Om dat soort uitspraken te kunnen doen is veel meer onderzoek nodig. Maar we wilden laten zien, kijk, met deze methode kun je vaststellen welke stereotypen er zijn en wat zij oproepen.’
‘Stereotypen konden verrassend snel verschuiven’
Tot slot keken de onderzoekers ook wat er gebeurt als je de taalmodellen verfijnt met extra data, zoals gebruikelijk is wanneer deze voor praktijktoepassingen worden ingezet. Daarvoor gaven ze de modellen extra training door ze enkele duizenden artikelen van een aantal specifieke media te voeren. ‘Wat daarbij opviel is dat de stereotypen verrassend snel konden verschuiven,’, vertelt Choenni. ‘Als we bijvoorbeeld de modellen trainden met artikelen van The New Yorker, zag je dat sommige termen die geassocieerd zijn met ‘police officer’ negatiever werden, terwijl als we artikelen van Fox News gebruikten de associaties met ‘police officer’ positiever werden.’ Waarbij ook voor dit experiment geldt: de conclusie is niet dat Fox News dus altijd positiever over politieagenten schrijft. Om dat te concluderen is ander en uitgebreider onderzoek nodig. Choenni: ‘Maar het laat wel zien hoe gevoelig AI taalmodellen zijn voor de data waarmee je ze traint, en hoe snel er verschuivingen in stereotypen kunnen optreden.’
Details van de publicatie
Rochelle Choeni, Ekaterina Shutova en Robert van Rooij; Stepmothers are mean and academics are pretentious: What do pretrained language models learn about you? Gepresenteerd op de 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP2021), 7 november 2021. Weblink naar de wetenschappelijke publicatie.